I'm Clément
—
part engineer, part entrepreneur, part (mad) scientist, building AI at DeepMind. In the past 15y, I've been driven by an obsession: figuring out how to build AI systems that can learn on their own and ultimately redefine how we write software.
My research initially focused on artificial vision in the early days of deep learning: from the design of
e2e trainable vision systems via
conv neural networks, to their computation on custom low-power computers (
NeuFlow).
Today, I focus mostly on transforming this type of research into high-leverage platforms and products that transform our industry and create value. I'm especially interested in how to build more general AI agents that can learn on their own, and figure out how to acquire optimal datasets to solve tasks.

I am a VP of Research at
Google DeepMind, building next-gen software to enable AI to be designed and scaled to its limit: systems that can ultimately match or exceed cognitive abilities of humans, dotted with agency and the ability to learn to improve further.

I was VP of AI Infra at NVIDIA for the past 6 years, leading 2 major projects:
MagLev - NVIDIA's AI infra, which powers
NVIDIA's Autonomous Vehicles, and
RAPIDS - NVIDIA's Data Science platform.
We launched Gemma, our first "open Gemini". This is v1, we have a lot more in our pipeline.
New Podcast (Sept'23)
More philosophical than the usual... sharing thoughts on bio intelligence vs AI.
Gemini!
We launched Gemini. This was an intense year long effort, to build the most capable AI on earth.
Levels of AGI
Our new write up attempting to define levels of AGI, to better understand our progress.
@Scale Keynote
Inside NVIDIA's AI infrastructure
for self-driving cars
Scaling SW 2.0 dev
Here I share my insights on enabling Software 2.0 development
LDV Summit 2023
A fireside chat with Evan Nisselson, about the past 10y of AI development, starting companies & productizing AI research.
NVIDIA AI Podcast
Here I go through the work we did at NVIDIA on AI for self-driving cars.
RAPIDS
NVIDIA's Data Science platform
NSFW @ Twitter
Press on the work we did at Twitter Cortex to filter out bad content
LDV Summit 2017
Here I give an overview of the state of the industry and my work circa 2017.

Before Twitter, I co-founded a company,
Madbits, focusing on image & video classification to enable search - it worked amazingly for private photo libraries and social media. We were one of the very first to provide such tech and sold it to Twitter.
Genius Makers
Some of the MadBits story is told in Cade Metz' book on the early days of Deep Learning.
Podcast
Here I talk about my early work on deep neural nets, with Ryan Adams.
Before that I was a research scientist at the
Courant Institute, New York University, for 5 years, where I worked towards my PhD (
Université Paris-Est) under the supervision of
Yann LeCun +
Laurent Najman.
My thesis:
"Towards Real-Time Image Understanding with Convolutional Networks".
In that time I was also one of the architects of
Torch with Ronan and Koray, which later became
PyTorch under Soumith's lead.
Torch
Torch is PyTorch's ancestor. It was Lua+C based and introduced many core concepts.
Research Topic - Scene Parsing (2010-12)
Scene parsing, or semantic segmentation, consists in labeling each
pixel in an image with the category of the object it belongs to.
It is a challenging task that involves the simultaneous detection,
segmentation and recognition of all the objects in the image.
Back in 2011, I had been working on a model (with
Laurent Najman
and
Yann LeCun)
that could parse a wide variety of scenes
in close to real-time on a regular computer.
I keep videos of this work here for posterity :) as the work was very early then.
In the following clips, recorded in random locations in the NYC area,
we demonstrate the generalization capabilities of our model. This
model was trained on the rather small
Stanford
Background dataset, which contains 715 images (520 for training,
the rest for testing), labeled into 8 classes.
 sky,
road,
building,
tree,
grass,
water,
mountain,
object.
sky,
road,
building,
tree,
grass,
water,
mountain,
object.
The next clip demonstrates generalization of our
larger model, trained on the
SiftFlow dataset, made of 2,688 images and 33 classes. The video was stitched from
4
GoPro cameras, and shot around the NYU campus. Our parse is far from perfect, but remember: our model doesn't perform any global inference, to maintain a high frame rate.
Research Topic - NeuFlow: A Dataflow Processor for Deep Neural Nets (2008-2011)
neuFlow is a custom dataflow computer that I
designed to optimally compute dense, filter-based vision models.
Dataflow processors like this one are well suited for high speed
processing of video streams, can be extremely compact, and could
give vision capabilities to any light-weight unmanned
vehicle with low power constraints.
Back then I was very interested in the low-power, efficient computation
of convolutional networks and the like. Yann LeCun
et al.
have demonstrated the efficiency of such architectures in
pattern/object recognition of images [
LeCun 1998
,
LeCun 2010
,
Kavukcuoglu 2010
,
Jarrett 2009
].
neuFlow is based on a reconfigurable grid of
simple processing units. Such a grid provides a way of dynamically
reconfiguring the hardware to run diff. operations on streams
of data, in parallel. The arch is inspired by the old
ideas of dataflow computing [
Adams 1968
,
Dennis 1974
,
Hicks Arvind 1993
].
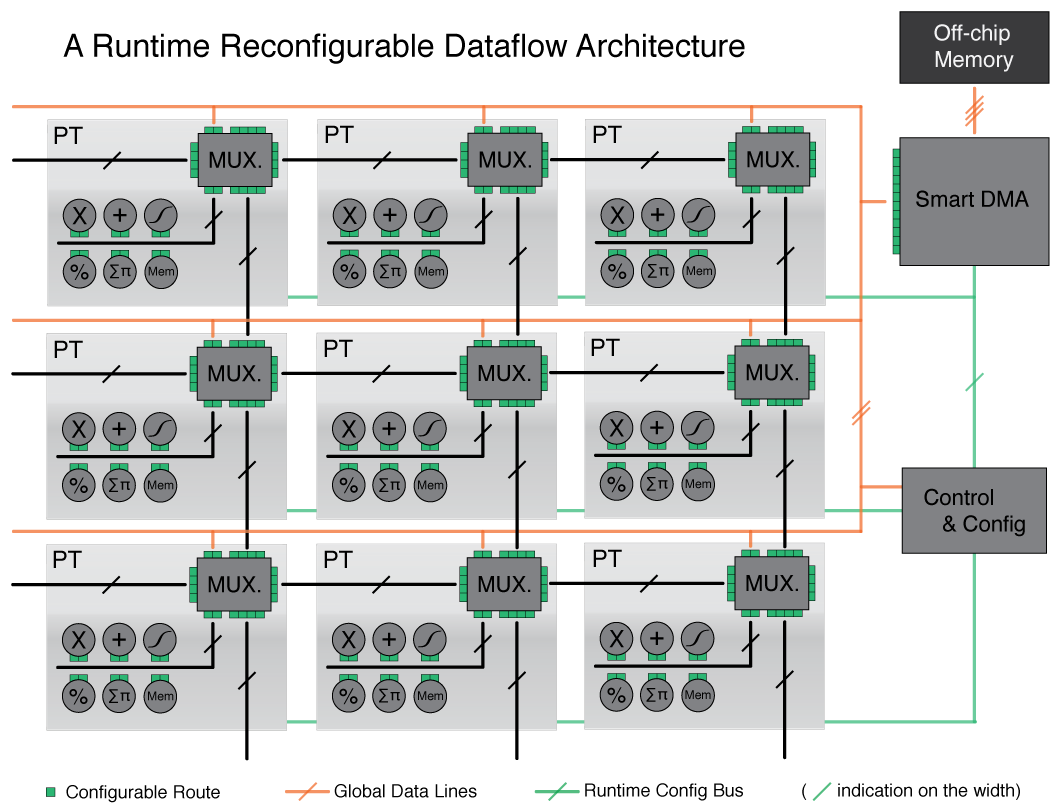
This figure shows an overview of the
neuFlow architecture.
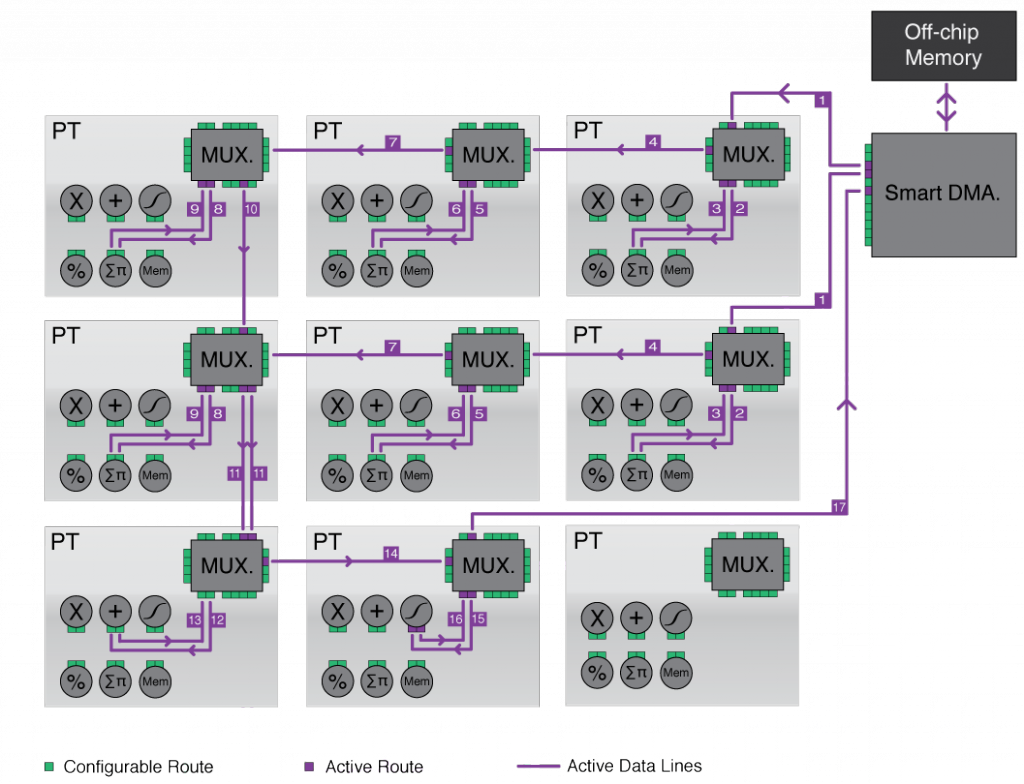
This figure shows our grid configured for a particular
operation: a non-linear mapping of a sum of 2D convolutions,
performed in one pass.
Our latest platform for
neuFlow was sitting on an 8-layer PCB I routed...
The platform embedded two cameras, 8GB of DDR3 memory, and one
of the largest Xilinx FPGAs. It was able to run my scene parsing model at 10fps+ on HD streams.
Research Topic - Convolutional Networks for Vision (2010-2013)
One of the key questions of Vision Science (natural and artificial) is how to produce good internal representations of the visual world. What sort of representation would allow an artificial vision system to detect and classify objects into categories, independently of pose, scale, illumination, conformation, and clutter? More interestingly, how could an artificial vision system learn surch representations automatically, the way animals and human seem to learn by simply looking at the world?
In the time-honored approach to computer vision (and to pattern recognition in general), the question is avoided: internal representations are produced by a hand-crafted feature extractor, whose output is fed to a trainable classifier.
While the issue of learning features has been a topic of interest for many years, considerable progress has been achieved in the last few years with the development of so-called deep learning methods.
Good internal representations are hierarchical. In vision, pixels are assembled into edglets, edglets into motifs, motifs into parts, parts into objects, and objects into scenes. This suggests that recognition architectures for vision (and for other modalities such as audio and natural language) should have multiple trainable stages stacked on top of each other, one for each level in the feature hierarchy. This raises two new questions: what to put in each stage? and how to train such deep, multi-stage architectures?
Convolutional Networks (ConvNets) are an answer to the first question. Until recently, the answer to the second question was to use gradient-based supervised learning, but recent research in deep learning has produced a number of unsupervised methods which greatly reduce the need for labeled samples.
A typical convolutional network for images:

Next is everything I published, in conferences, journals, books, blogs, and patents.
Find me on
Google Scholar for data.
Arxiv
Levels of AGI: Operationalizing Progress on the Path to AGI
Meredith Ringel Morris, Jascha Sohl-dickstein, Noah Fiedel, Tris Warkentin, Allan Dafoe, Aleksandra Faust, Clement Farabet, Shane Legg,
ArXiv, Nov 2023.
Blog post
Wrapping up my journey scaling Software 2.0 development for AV
Clement Farabet,
Medium,
Nov 2022.
Arxiv
Active Learning for Deep Object Detection via Probabilistic Modeling
Jiwoong Choi, Ismail Elezi, Hyuk-Jae Lee, Clement Farabet, Jose M. Alvarez,
ArXiv preprint, March 2021.
Arxiv
Scalable Active Learning for Object Detection
Elmar Haussmann, Michele Fenzi, Kashyap Chitta, Jan Ivanecky, Hanson Xu, Donna Roy, Akshita Mittel, Nicolas Koumchatzky, Clement Farabet, Jose M. Alvarez, ArXiv preprint, Oct 2020.
Arxiv
Training Data Distribution Search with Ensemble Active Learning
Kashyap Chitta, Jose M. Alvarez, Elmar Haussmann, Clement Farabet, ArXiv preprint, Sept 2019.
Arxiv
Less is More: An Exploration of Data Redundancy with Active Dataset Subsampling
Kashyap Chitta, Jose M. Alvarez, Elmar Haussmann, Clement Farabet, ArXiv preprint, May 2019.
Conference Proceedings
Deep Active Learning for Object Detection with Mixture Density Networks
Ji-Woong Choi, Ismail Elezi, Hyuk-Jae Lee, Clement Farabet, Jose M. Alvarez, ICLR, 2021.
Conference Proceedings
Scene Parsing with Multiscale Feature Learning, Purity Trees, and Optimal Covers
C. Farabet, C. Couprie, L. Najman, Y. LeCun, in Proc. of the International Conference on Machine Learning (ICML'12), Edinburgh, Scotland, 2012.
Conference Proceedings
NeuFlow: Dataflow Vision Processing System-on-a-Chip
Phi-Hung Pham, Darko Jelaca, Clement Farabet, Berin Martini, Yann LeCun and Eugenio Culurciello, in IEEE International Midwest Symposium on Circuits and systems, IEEE MWSCAS, 2012, Boise, Idaho, USA.
Conference Proceedings
NeuFlow: A Runtime Reconfigurable Dataflow Processor for Vision
C. Farabet, B. Martini, B. Corda, P. Akselrod, E. Culurciello and Y. LeCun, in Proc. of the Fifth IEEE Workshop on Embedded Computer Vision (ECV'11 @ CVPR'11), IEEE, Colorado Springs, 2011. Invited Paper.
Conference Proceedings
Hardware Accelerated Convolutional Neural Networks for Synthetic Vision Systems
C. Farabet, B. Martini, P. Akselrod, S. Talay, Y. LeCun and E. Culurciello, in International Symposium on Circuits and Systems (ISCAS'10), IEEE, Paris, 2010.
Conference Proceedings
Convolutional Networks and Applications in Vision
Y. LeCun, K. Kavukcuoglu and C. Farabet, in International Symposium on Circuits and Systems (ISCAS'10), IEEE, Paris, 2010.
Conference Proceedings
An FPGA-Based Stream Processor for Embedded Real-Time Vision with Convolutional Networks
C. Farabet, C. Poulet and Y. LeCun, in Proc. of the Fifth IEEE Workshop on Embedded Computer Vision (ECV'09 @ ICCV'09), IEEE, Kyoto, 2009.
Conference Proceedings
CNP: An FPGA-based Processor for Convolutional Networks
C. Farabet, C. Poulet, J. Y. Han, and Y. LeCun, in Proc. International Conference on Field Programmable Logic and Applications (FPL'09), IEEE, Prague, 2009.
Conference Proceedings
Visual Tracking and LIDAR Relative Positioning for Automated Launch and Recovery of an Unmanned Rotorcraft from Ships at Sea
M. Garratt, H. Pota, A. Lambert, S. E.-Maslin, and C. Farabet. In ASNE Conf. on Launch and Recovery of Unmanned Vehicles From Surface Platforms 2008, Annapolis, May 2008. American Society of Naval Engineers.
Journal Paper
Toward real-time indoor semantic segmentation using depth information
Camille Couprie, Clement Farabet, Laurent Najman, Yann LeCun, Journal of Machine Learning Research, 2014.
Journal Paper
Convolutional nets and watershed cuts for real-time semantic Labeling of RGBD videos
Camille Couprie, Clement Farabet, Laurent Najman, Yann LeCun, Journal of Machine Learning Research, 2014.
Journal Paper
Learning Hierarchical Features for Scene Labeling
Clement Farabet, Camille Couprie, Laurent Najman and Yann LeCun, IEEE Transactions on Pattern Analysis and Machine Intelligence, in press, 2013.
Journal Paper
Comparison Between Frame-Constrained Fix-Pixel-Value and Frame-Free Spiking-Dynamic-Pixel ConvNets for Visual Processing
Clement Farabet, Rafael Paz, Jose Perez-Carrasco, Carlos Zamarreno, Alejandro Linares-Barranco, Yann LeCun, Eugenio Culurciello, T. Gotarredona and B. Linares-Barranco, Frontiers in Neuroscience, 2012.
Journal Paper
Visual Tracking and LIDAR Relative Positioning for Automated Launch and Recovery of an Unmanned Rotorcraft from Ships at Sea
M. Garratt, H. Pota, A. Lambert, S. E.-Maslin, and C. Farabet, Naval Engineers Journal, vol. 121, no. 2, pp. 99-110, June 2009.
Patent
Training, testing, and verifying autonomous machines using simulated environments
Clement Farabet, John Zedlewski, Zachary Taylor, Greg Heinrich, Claire Delaunay, Daly Mark, Campbell Matthew, Curtis Beeson, Gary D. Hicok, Michael Brian Cox, Lebaredian Rev, Tamasi Tony, Auld David, applied 2019, granted 2022.
Patent
Distributed Neural Network Training System
Shen; Yichun, Li Siyi, Wen Yuhong, Farabet Clement, applied 2022.
Patent
Systems and methods for safe and reliable autonomous vehicles
Michael Alan Ditty, Gary D. Hicok, Jonathan Sweedler, Clement Farabet, Mohammed Abdulla Yousuf, Tai-Yuen Chan, Ram Ganapathi, Ashok Srinivasan, Michael Rod Truog, Karl Greb, John George Mathieson, Nister David, Kevin Flory, Daniel Stewart Perrin, Dan Hettena, applied 2019.
Patent
Runtime reconfigurable dataflow processor with multi-port memory access module
Clement Farabet, Yann LeCun, applied 2012, granted 2018.
Book Chapter
Large-Scale FPGA-Based Convolutional Networks
C. Farabet, Y. LeCun, K. Kavukcuoglu, B. Martini, P. Akselrod, S. Talay, and E. Culurciello (2011). In R. Bekkerman, M. Bilenko, and J. Langford (Ed.), Scaling Up Machine Learning. Cambridge University Press, 2011.
PhD Thesis
Towards Real-Time Image Understanding with Convolutional Networks
C. Farabet, PhD (2013). PhD Thesis. Universite Paris-Est.
Workshop
NeuFlow: A Runtime Reconfigurable Dataflow Processor for Vision
C. Farabet, Y. LeCun, in Big Learning Workshop (@ NIPS'11), Sierra Nevada, Spain, 2011. Invited Talk.
Workshop
Torch7: A Matlab-like Environment for Machine Learning
R. Collobert, K. Kavukcuoglu, C. Farabet, in Big Learning Workshop (@ NIPS'11), Sierra Nevada, Spain, 2011.
Workshop
NeuFlow: A Runtime Reconfigurable Dataflow Processor for Vision
C. Farabet, Y. LeCun, E. Culurciello, in Snowbird Learning Workshop, Fort Lauderdale FL, 2011.
Workshop
Hardware Accelerated Visual Attention Algorithm
P. Akselrod, F. Zhao, I. Derekli, C. Farabet, B. Martini, Y. LeCun and Eugenio Culurciello. In Proc. Conference on Information Sciences and Systems (CISS'11), IEEE, Baltimore, 2011.
Workshop
A Dataflow Processor for General Purpose Vision
C. Farabet, P. Akselrod, B. Martini, K. Kavukcuoglu, B. Corda, S. Talay, E. Culurciello and Y. LeCun, presented at Neural Information Processing Systems (NIPS'10), Vancouver CA, December 2010.
Workshop
Building Heterogeneous Platforms for End-to-end Online Learning Based on Dataflow Computing Design
B. Corda, C. Farabet, M. Scoffier and Y. LeCun, in Workshop on Learning on Cores, Clusters and Clouds (LCCC @ NIPS’10), Whistler CA, December 2010.
Workshop
A Study of Parallel Computing for Machine Learning: Which Platform for Which Application
B. Corda, C. Farabet and Y. LeCun, presented at the 4th Annual Machine Learning Symposium at the New York Academy of Sciences, New York, October 2010.
Workshop
NeuFlow: a Vision Processor for Real-Time Object Categorization in Megapixel Videos
C. Farabet, presented at AIPR Workshop, Washington DC, October 2010.
Workshop
NeuFlow: a Dataflow Computer for General Purpose Vision
C. Farabet, presented at e-lab's Seminar Series, Yale University, October 2010.
Workshop
Bio-Inspired Processing for Ultra-Fast Object Categorization
C. Farabet, B. Martini, P. Akselrod, S. Talay, Y. LeCun and E. Culurciello, in High Performance Embedded Computing (HPEC'10), MIT Lincoln Laboratory, Lexington, 2010.
Workshop
An FPGA-based Processor for Convolutional Networks
C. Farabet, C. Poulet, J. Y. Han, and Y. LeCun, in Snowbird Learning Workshop, Clearwater FL, 2009.
Master's Thesis
Hardware implementation of a convolutional neural network – design of a neural processor
C. Farabet, Master’s thesis, INSA Lyon, France – New York University, New York, USA.
Undergrad Thesis
Implementation of a tracking system within an fpga
C. Farabet, University of New South Wales at ADFA, Canberra, Australia, Technical Report, July 2007.
Ok and because you made it this far... here's some music I recorded over the years... enjoy.
This is mostly my own, and inspired by various things I used to listen to.
Some of it is recorded with real tube amps (mostly Victory amps), the rest with Neural DSP's emulators, which are plain amazing... (I used to be so picky about tube amps, now I can't make the difference).
Random musings
Recorded over the years...
Transfer
Composed circa 2004, re-recorded in 2022.
Day One
by The 13th Block. Recorded in Lyon circa 2002.




 Before joining NVIDIA, I started a team at Twitter called Cortex, which built a high-leverage Deep Learning platform to power every aspect of the Twitter product (recommendation systems, search, timeline ranking, filtering).
Before joining NVIDIA, I started a team at Twitter called Cortex, which built a high-leverage Deep Learning platform to power every aspect of the Twitter product (recommendation systems, search, timeline ranking, filtering).